I started looking for datasets I can use in my project and found a few:

2. HaGRID dataset:https://github.com/hukenovs/hagrid

I first decided to use GestureLeapRecog dataset:
Pros:
- High Precision and Rich Features: The Leap Motion sensor captures detailed hand and finger movements with high accuracy, providing valuable data for developing robust gesture recognition models. arXiv
- Specific Application Focus: Tailored for hospital environments, the dataset includes a defined gesture vocabulary and a substantial number of samples, making it suitable for developing touchless control systems in medical settings.
Cons:
- Limited Generalization: Datasets captured using specific sensors like the Leap Motion may not generalize well to other devices or real-world scenarios without additional data augmentation or cross-device validation.
- Environmental Constraints: The performance of the Leap Motion sensor can be affected by lighting conditions and occlusions, which may introduce noise or inaccuracies in the dataset.
First, in order to prepare my dataset to be fed to the model, I preprocessed the images:

This code walks through a folder of gesture images, loads each image, and prepares it for use in a machine learning model by assigning it a numeric label and storing it in training arrays. It begins by looping through all the top-level directories in a specified drive_folder, which are assumed to represent different users or categories. For each of these directories, it then looks for gesture-specific subfolders like 01_palm, 02_fist, and so on. If a gesture folder hasn’t been seen before, the code assigns it a new numeric label using a counter (class_index). It then loops through all the .png image files in that gesture folder, loading each one in grayscale using OpenCV. Each image is resized to a fixed size (IMG_WIDTH × IMG_HEIGHT) and normalized to have pixel values between 0 and 1. Valid images are added to the list X, while their corresponding gesture label is added to y. As a result, X becomes a collection of processed image arrays and y holds the corresponding numeric class labels, with a dictionary gesture_labels mapping folder names to label indices. This setup is commonly used to prepare gesture datasets for training image classification models in Keras or PyTorch.
After preprocessing, I divide the dataset into training and testing data and one=hot encode raw labels.

Since I am recognising static gestures, the Convolutional Neural Network (CNN) because it’s specifically designed to handle image data by automatically learning spatial patterns and visual features.
This CNN is designed to:
- Take in 128×128 grayscale gesture images.
- Pass them through 3 convolutional blocks to extract hierarchical visual features.
- Flatten and feed them into a dense network to make a final classification.
- Output a probability distribution over 10 gesture classes.

After training the model for 20 epochs these are the results:

Although my model achieved nearly 100% accuracy on both training and validation sets, this was likely due to repeated or highly similar frames appearing in both splits. To better test generalisation, I plan to and introduce stronger augmentation and an independent test set.

These are results after applying heavy augmentation and retraining the model:

This is a much healthier learning curve. After applying heavy augmentation (random shifts, rotation, brightness changes), the model showed slower but more robust learning. Validation accuracy surpassed training accuracy early on, indicating that the model was learning to generalise rather than overfit. The smoother loss curves confirm that augmentation made training more challenging and helped the model better handle real-world variation in gestures.
No matter how healthy the accuracy curve looks, I also decided to calculate the confusion matrix and F1 table.
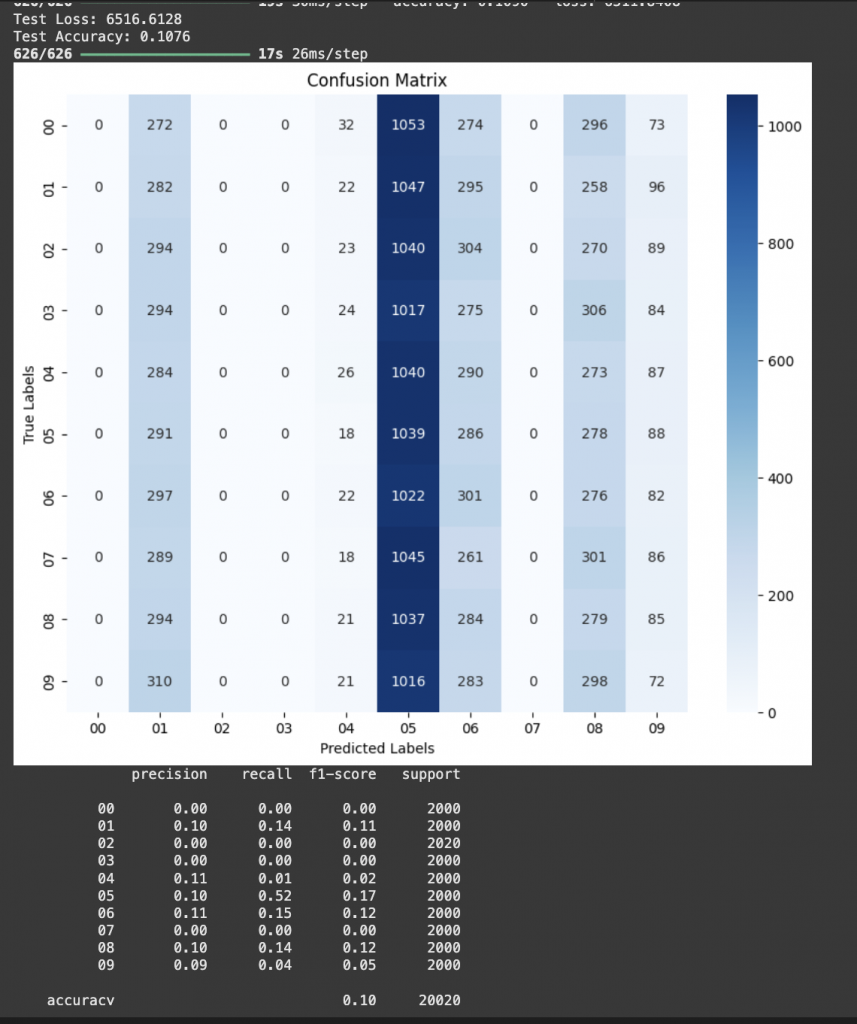
Despite achieving high training and validation accuracy during model development (with validation accuracy exceeding 95% after data augmentation), my final evaluation on a separate test set resulted in unexpectedly low performance — with a test accuracy of only 10.76% and a confusion matrix dominated by predictions in a single class. This mismatch indicated that the model, although seemingly robust on validation data, failed to generalize to the test set.
Upon inspection, the confusion matrix revealed that nearly all test samples were predicted as class 05, regardless of their true label. This pointed to a deeper issue — not overfitting, but likely a distribution mismatch, data leakage, or mislabeling during test preparation. One probable cause was that the test set consisted of samples visually different from those seen during training and validation (e.g., different lighting, gesture speed, or user hand), or that labels were inadvertently shuffled or misaligned during test data loading.
This result highlights a key lesson from the project: a model’s validation accuracy does not always reflect real-world performance, especially if the validation set is not strictly separated by user, video, or recording session. In future iterations, I would ensure a stricter separation between training/validation and test data (e.g. user-independent or time-split partitions), and verify label alignment before evaluation.
After tweaking some of the parameters ( added L2, increasing L2, increasing Dropout layer), it did not help much. This is the last confusion matrix:

Even though the model stopped classifying everything as one class, it also is far from being very accurate.
After that, I decided to change the architecture of the model. In this version of the CNN, I used a compact two-layer convolutional structure with 32 and 64 filters, followed by a single dense layer with 128 units and dropout. Compared to earlier models with more layers or higher capacity, this architecture is lighter and faster to train, while still capable of achieving high accuracy on clean gesture datasets.


In this training run, my model achieved 100% accuracy on both training and validation data within the first two epochs, and maintained it across 15 epochs. The final confusion matrix showed perfect classification across all 10 gesture classes, with no misclassifications. While this result suggests the model learned the task extremely well, the outcome likely reflects the controlled nature of the dataset — with consistent lighting, isolated gestures, and minimal background noise. I double-checked for data leakage and label mismatch to ensure the result was valid. In future iterations, I aim to test the model on more challenging, real-world gesture data to further validate its robustness.
Conclusion
Although my goal was to connect a gesture recognition model to Leap Motion for interactive control, I quickly realized that the dataset I chose had major limitations that prevented meaningful results. As shown in the image below, the dataset contains dozens of nearly identical grayscale frames captured from a single gesture instance — with little to no variation in hand position, lighting, or background. These are essentially consecutive video frames of the same gesture, which means the model can easily memorize pixel patterns without truly learning to generalize across different gesture styles or users. While it achieved high accuracy during training and validation, this was misleading: the model was simply memorizing repeated frames rather than recognizing gestures in a meaningful way. For real-time gesture recognition, the model must be exposed to diverse hand shapes, angles, speeds, and lighting conditions — which this dataset lacks. In short, the dataset was not rich or varied enough to support my objective of building a robust gesture classifier that could work with Leap Motion data.
Link to the google collab notebook: https://colab.research.google.com/drive/1wZ4FT2jqyV18kArN_r66dmPRjLzD5ohz?usp=sharing
Leave a Reply